Details
Dates: Tuesday 21 October 2014 - Wednesday 22nd October 2014
Location: British Museum, British Library
Institutions Present:
- ArtStor
- Bibliotheque Nationale de France
- Biblissima
- British Library
- British Museum
- C2RMF (The Louvre)
- Cornell University
- Europeana
- e-codices
- Harvard University
- National Library of Poland
- National Library of Denmark
- National Library of Wales
- National Library of Norway
- Oxford University
- Princeton University
- Stanford University
- Wellcome Library
- Yale University
Actions
- Need IIIF Wikipedia Page - Tom Crane will take a start
- Should Screencast 0-60 - Jon and Rob
- Make it clear that Image and Prezi APIs intend to stay on 2.x.y (i.e. backward compatible) for a long time (Neil)
- Consider a Javascript SDK for Prezi API (Drew, Matt, Jon, Rob, Ed)
- Finish REST document (Jon and eds)
- Create a google doc with museum contacts (Rob)
- Further discussion of Prezi API REST (Oxford, Yale, Stanford, Princeton, Cornell)
- Experimental implementations of interoperable client/server for annotation management (Stanford, Yale, NL Wales, Harvard)
- Tutorial for IIIF Presentation API (Drew, Raphael [as non-editors])
Issues Raised
- Image Validator could optionally (opt in) add the image server to a registry
- Need an XML Image Sitemap validator (Chris Beer/Stanford has one)
- Somewhere in the manifest’s json-ld point to a viewer instance that renders the current manifest eg {“viewer” : “http://example.org/mirador?http://example.org/iiif/manifest.json”}
Contents
{.toc}
Outreach feedback / Ideas for future sessions
- 0-60 as we did it may give the opposite impression (i.e. that it’s difficult) (Anders)
- More implementer stories in the morning (Ege, but also E-codices, Yale), maybe push tech into the afternoon. (Stu, others)
- Demo integration with existing systems (Markus) (e.g. ContentDM, Stu)
- Put the Prezi API in context with other metadata standards to explain that it’s not one (Jon)
- Who are our audience? Technical, managerial? Maybe we need two tracks? (Peter, Jon)
- A little bit about JSON-LD might be useful?
- Linked data didn’t come through at all
Technical sections lost some people. Creation of manifests – writing code not good, but UI version might work? Need e-codices and/or Oxford creation tools.
Sequence for the day: Front load with case studies. Shows power and value. Use cases are motivating to stay to find out how to do it. Then move technical content to the end.
Didn’t show: Integration with other systems, catalogs, search tools, repository systems, etc. This meant it felt a bit stand alone.
ContentDM shim as an example – helps smaller institutions, demonstrates not hard. Nearly free to get it up and running on top of a commercial system.
Who do we need to convince? Crafting an argument to convince senior leadership – good for membership but not necessarily for technical. IIIF is technical, if it’s watered down it might not be the right strategy. Two audiences – mgmt and devs. Also museums / libraries different audiences. Easier to sell developers on interoperability than management.
Open access not necessary – should highlight authentication as possible. IIIF as a presentation layer for images, not for search etc.
Focus – getting significant collections available. Several MSS to reassemble virtually. eg BNF, BL, Oxford
Oxford: IIIF Mellon project has funds towards 4 exemplar projects. Open bid process. When is the bidding going to be opened?
British Museum project – spanning collections, Book of the Dead. Would be great to demonstrate. Also integrate with Harvard MOOC on egyptian heiroglyhs.
Need a list of museums to work with towards critical mass
Museums often need a DAM – could bundle IIIF image server. Less use of standards than library world. CIDOC-CRM very rare. Could be an easy sell due to its ease of use and practical nature.
Linked Open Data is a trend, didn’t come through as well as it could. Could be a selling point.
Funding/community possibilities:
- Maybe talk to JISC. Getting people together.
- Europeana level might be better? Opens up H2020 money perhaps.
- Lots of work done in TEL. Would like adoption of IIIF, so portal has better access. Might provide a backup of images. Also interested in presentation API. Lot of the work is already done, via EDM. Added value for data providers. Europeana provides an index, helps with discovery. Provide tools to the content providers.
Triage of Open Issues
- #9 Auth & Rights - high priority
- #96 Search results - 90% interest
- #40a REST annotations - 90% interest
- #227 Attribution in Image API (give attribution and rights in image API) - 90% interest
- #294 Feedback from Google: Image compression necessary (can be readily added, not breaking) - 70%
- #39 Dynamic annotation list (more general than IIIF, can’t wait for W3C group as this is 2016 end, how do we put in pointer to service to get annotations?) - 50%
- #207 Bounds for annotation viewing (Drew argues conflates two features: z axis and information, what about annotation retrieval based on bounding box, perhaps ties with dynamic services, Neil mentions question of ordering of annotations but notes multiple criteria (say importance or size)) - perhaps roll search within bounding box with #39? - 50%
- #80 Object (Manifest) level annotations, not canvas (use cases: crowdsources description, commentary) - 45%, likely quick
- #40b REST for remains of Presentation API (Oxford use case for manifest authoring as part of digitization workflow. Need auth first) - 35%
- #21 REST for Image API (Kevin Clark has use case on f4 list for this. Consensus that create and delete OK, not sure about update. Need auth first) - 20%
- Also #40, #215
- May depend on Auth?
- Prezi for Annotation/Prezi content (Oxford editor use case)
- Image for Image (Fedora, Oxford, Princeton use cases)
- #215, #377 are impl details to be worked out when/if we work on this
- #76 Presentation compliance? (have image api compliance but no similar notion for presentation api, requirements are more on the viewer, one argument is table on website to describe viewer capabilities) - 20%
- #82 Intended Audience for Layer/AnnoList? (machine vs human, how different from other groupings? could it be just a different motivation) - 18.5%, not too hard
- #42 SharedCanvas Zones in IIIF (spatial grouping of annotations on canvas. Newspaper use case @ BL, Julie Alinson @ York, Maryland? How far can we get with Ranges? Ranges allow grouping but no object to manipulate) - low priority + complicated, continue to defer
- #56 How do range order and sequence order interact (tricky question) - not a priority until we have use cases with multiple sequences, however consensus that not hard
- #99 Should presentation have Protocol? (provides one line test for something being a Manifest, would be a breaking change) - defer to 3.0
- #293 Confidence/error bounds for physical scale (uncertainty about UI presentation, not sure how many places have error bounds) - defer for more need/use-cases/clients - 0%
Authentication/Authorization Use Cases
Wellcome
Currently gives different manifests for different users, but not fond of this approach. Would like to have a service that provides information as to whether the user is authed or not, and where to go to acquire the credentials. Not a IIIF problem to do auth, but instead to allow clients to do auth. No implications as to what happens at the other end of the URI that is provided to the client, typically a login page. Maybe a callback URI, ala single sign on. Assumption is that the Manifest is open / not protected. Ranges can say which bits are protected.
Use case – almost always entire objects restricted. 99% are the same – archives of people less than 100 years old, just need to accept T&C. A few parts of objects not available to everyone.
Dont do degraded access at the moment. Service could return some document that gives the restrictions (eg max size, degraded, etc)
For can’t see objects, thumbnail is still available. Thumbnails for the first level (T&C) aren’t access controlled. Edge case of personally identifiable face in the thumbnail. Need to make those one level up where you can’t get the thumbnail without a credential.
Issue with cross-institution images, where image is used in someone else’s manifest.
Requirement to handle 403 on a manifest reasonably. Degraded manifest is either no use case, or a different URI. Important for manifest to have a stable URI.
Stanford
Manifests wide open, usable. Subscribers get full access to the image, non subscribers get a degraded image. currently based on maximum size of image. Users without access get thumbnail only. Tiles open, only auth’d users can get full size for download.
British Library
Auth as a means to enforce rights. Proxy in front of API server, responsible for auth. Integrated with Shibboleth. User role, user location - reading room vs external.
Manifests can be open or not visible. Same with image api requests. Proxy would just block them with 403. Question as to how to fail gracefully. Viewer can be embedded into external websites, which has issues re rights attribution and branding. Other viewers embedded in websites might not do this, so need to have concept of a trusted viewer. Thinking about API keys. Not sure how to provide it yet. Attribution is the requirement. E.g. Stanford can deliver BL content, but only if BL logo is displayed. Not for all content, some is open.
National Library of Wales
Project website with other people’s digitized content, but not allowed to show it elsewhere. NL Wales publishing someone else’s content. Some images allow zooming, but also provide for sale high quality version. Want to provide good quality, without jeopardizing sales.
Also physical location – some content only available within the building. Physical location basically IP range. Need to get user to the place where they understand why they don’t have access.
National Library of Norway:
Location related. Some only accessible inside NLN, some only on internal network. Some only in Norway, some everywhere. So far only at the manifest level, not the single page level. Some objects can be viewed, some download as PDF, some as high quality images. Object, user, and permitted action.
Single user and role implemented but not yet widely used. If credentials from the user matches the credential on the object, you have access to that object at that level.
Princeton:
Roles, location. Stanford case of zoom but not download. Possibly download full with downgraded version. Watermarking use case – name of donor has to be in the margin for non authed. Copyright material – same use cases apply. Have to be on campus.
National Library of Poland:
Local in reading room versus external. Watermarking with project name. Possibility to check HTTP referrer header.
Cornell:
Nothing to add beyond cases already covered.
Yale:
Location. Roles as useful, eg curator of museum can get full resolution but public gets only thumbnail. Publishing tiles, not worried about scraping as open access by that point. Can get the full resolution image for open content. Don’t provide a download button, but don’t take any measure to stop people crafting the right URI.
CRUD based on user and group, corresponds to projects, for annotation lists. If there’s an authentication required annotation, you just don’t get it in the list. Not told of empty annotation lists. Get list of lists of annotations that you can see, each will have at least one.
Would be useful to allow the not authed user to know that there might be more annotations after signing in. Need negotiation at the canvas level, or aggregate up to the manifest level. Also don’t want to be told there’s things you can’t get.
Europeana:
Licenses where providers give low res images and redirected through portal to the full image content. Need to have credentials for some of these cases.
e-codices:
Not for the metadata. Open access as curated by e-codices. Don’t serve PDF/TEI that have copyright. All images cc-by-nc. Some institutions might want to opt out in the future. Might restrict to max resolution of the image available.
NC not enforcable, BY is the attribution case, ala BL. Image metadata has to be preserved, embedded in the image. Have material digitized that isn’t displayed. Might be only displayed elsewhere, like owner’s website, but served from e-codices.
National Library of Denmark:
Hypothetical cases where can’t distribute content freely. Mostly for legal reasons, or to sell copies. Similar to the BL setup, if we deliver the data, then it can be used. If protected just don’t deliver it. Could use degraded delivered images. Annotations might be first use case to come across for auth.
C2RMF / IIP Server adopters:
C2RMF archive not available generally, but is to partner institutions. Makes auth simpler. Role based auth, similar to Stanford. Thumbnail only, pan/zoom with tiles, export region/full at a given maximum size. SOme have access to the full image.
Rembrandt project, Cranach concerned about reuse of the images. Cranach: watermarking dynamically on certain tiles. Everyone gets the watermarking. Technical limitation on how much you can protect an image, but it was sufficient to get the images online.
Harvard:
HarvardX only uses open images. Library has auth, checks if harvard or not. Also do IP restrictions. Would like auth of groups. Some images have max size restriction for download. Public, Restricted, Not at all. Most image sets are public, manifests are all public. Max size for everyone, even at Harvard.
Using LTI/EdX for auth control for HarvardX, so will be before the viewer.
Biblissima:
Digital Library of Medieval Manuscripts, auth system for restricted by libraries. Discussed and decided to only produce manifests for open content.
BNF:
Gallica needs to know if the document is free to use or not. If not, then only in the reading room. Know this through the IP range. Can’t get download for not free to use documents. For audio tracks, in access full in the reading room, get popup when trying to access outside.
Artstor:
Different collections from institutions. Want to make it available.
- 200k common content available. Public domain.
- Contributions, e.g. museums give to artstor to share with other artstor subscribers.
- Collections can be limited to institution that provided it. Via IP range, login, shibboleth.
Metadata cough Presentation and images have the same protection. Some want per item rather than collection
Oxford:
Three levels of access:
- No access
- Partial or degraded. Could be pan/zoom but no download, or maximum resolution.
- Full
Want to restrict by authorization (password, shib, etc) IP Range, geo location. Restrictions on images only, but could imagine restricting annotations.
Authentication Discussion
Went through authentication scenarios
If an authenticated user makes a degraded image/manifest (which will have a different URI), should they be redirected to the higher-quality one? (or simply provide awareness?)
what happens in case where user credentials expire while they are viewing? how are they made aware?
what are the auth implications of requiring a trusted app (per BL)?
- should there be special support for the need of a trusted app separate from other auth description?
- are there types of “denied” in machine readable form rather than just option to redirect to a page with appropriate message
- question of weaker forms of assurance (such as a set of approved applications, where there could be forged application identity) would be adequate
implementation issues with javascript
- doesn’t get headers
- doesn’t see redirects (so wouldn’t see redirect to degraded version)
- therefore need to add extra to info.json
- no current requirement to get info.json first (but perhaps normal)
should there be a way to specify at the manifest level some known/likely set of auth services that will be necessary to access the set of images?
- might work nicely for federations
should we specify a mechanism?
- oauth good for public
- sso federations important for univs
- do we need certain requirements to support some set of auth methods?
various auth won’t support callback. Client can send user off to auth and then have “reload” to recheck credentials. This is perhaps the baseline case
Discovery of Objects
- Places that have Manifests but not Images
- Places that have Images but not Manifests
- Places that have both
Google sitemaps have an Image based extension to populate google image search, can add extentions to these. Could add a IIIF based attribute/xml doc. Logical place for it to live is the root of the image server eg {server}/{prefix}/image_sitemap.xml
Manifests: IIIF Collection of collections at a (well) known location. Can do both.
<urlset>
<url>
<loc> http://example.org/openseadragon?img=blackcat </loc>
<image:image>
<image:loc>http://example.com/iiif/page7/full/pct:10/0/default.jpg</image:loc>
<iiif:service>http://example.org/iiif/page7</iiif:service>
<iiif:inManifest>http://example.org/prezi/blackcat.json</iiif:inManifest>
<image:caption>Black Cat, by Rembrandt, provided by the BL</image:caption>
<image:title>Page 7</image:title>
<rs:ln rel="describedby" href="http://my/metadata/about/this"/>
<rs:ln rel="something here" href="my/manifest.json"/>
<image:license>http://creativecommons.org/CC-BY-NC</image:license>
</image:image>
</url>
</urlset>
Search within Object Use Cases
National Library of Wales:
Newspaper. Want to get the article location as well as the word location. Response of the query needs the range. Query syntax – “quoted phrase”, AND OR etc. Filtering annotations.
Wellcome:
Search in the full text and return resultset that says this is the canvas, at these coordinates, and the context on either side of the hit. How to identify the terms in the result that led to the hit. Not easy for client to determine. Can return html with around the words
National Library of Norway:
Search in the full text words or phrases. return set of coordinates for each hit. Don’t limit the search - don;t have the QA on article detection. Might come.
Stanford:
MSS - full text search. Plus ability to search general commentary annotations. Return RoI for hits. How to handle non unicode characters? (a: don’t :( ) Classes of annotations, eg lists and layers, canvas Future: bounding cube search
Princeton:
Defer :)
Cornell:
Defer :)
Europeana:
Possible to search only in the metadata currently, not the full text. Would like to have search on the comment annotations. Would like to be able to search full text.
Yale:
Search within a bounding box eg on large scroll. Search for tags as annotations
In the future: Search for things other than text? Annotating music audio file on to the canvas, can we search for all audio file annotations? Search for other than text – annotate values from multispectral analysis, can we search numeric data? e.g. text with data tables in it.
Harvard:
HarvardX – annotation searching, rather than full text. Library – full text search within object. Doesn’t know where in the image, just the canvas.
e-codices:
Only provide search across, not within. Don’t expose TEI data. Perhaps search for title, incipit, explicit, decoration.
National Library of Denmark:
Use case, have digitized books of published letters, ocr-ed and treated as separate objects, in TEI and served as individuals. Would like to go back to show the book pages that the letter came from. Literary corpus, scanned books, marked p TEI. Poems or plays or structured content, would like to extract and identify. Potential for search on top of that data.
Search in annotations. Musical scores as well, would be interesting. Encoded in MEI.
C2RMF / IIP :
Uses annotation to associate data with areas, not textual. Links to other resources in the database. Search is automatic at the DB level. So not sure if there’s a case for search within here.
Biblissima:
Have transcriptions in TEI. In the future will have more editions. Alignment is at the page level. Would like to have search in the future that resolves to the page. Search within commentary annotations.
BNF:
Gallica, can search full text as well as metadata. Use Cloudview. Depends on a particular company. Next iteration will have more advanced search. Work to improve the relationship between mets/alto. Not looking to expose functionality at the moment.
Oxford:
Search full text. TEI, some Alto, some plain text. All of the above :) Experimental image search – show hits that look like this. eg shared iconography
Synthesis:
In Scope
- Full text and comment annotations
- Return: Range(s), Canvas, coordinates. Hit, plus textual context on either side.
- Desire: search within a bounding box, within canvas, within an annotationList, within a range, within a layer, within a sequence
- How to refer from a manifest/range/canvas/list/layer to the search service
- Parameters to the search service
- functional equivalent of services that already exist
- error conditions, graceful degradation
Out of Scope
- Non textual content
- Federation makes sort client side only – relevancy is a particular sort and thus out of scope
- Metadata
- text query syntax (eg AND/OR/phrase/NOT) not in scope
REST – Use Cases for Image Management.
Shared tooling as a benefit.
Princeton:
Image repository gets a TIFF, not part of the image server. Then make a JP2 and send it to an image server. Never talked about “source image” in the docs, and REST requires such a thing. Can’t get the source image.
Oxford:
Introduces complexity in the current APIs. But would be optional addition. Would be rerouted away from front end server to a repository. Asset management versus image delivery often two separate systems. Scholars have their own photographs of objects and want to make them available.
Denmark:
User generated content could be a use case for us, would consider best practices when it becomes a higher priority.
REST – Manifest Use Cases
Oxford
Manifest management UI, browser based editing tool. Auto generate a manifest from a digitizatio workflow and then tidy it up. NB Requires auth!
Princeton:
Similar tool imagined. Given a list of images, create a basic sequence and then tidy it up.
Yale:
Scholars to upload and arrange images from chinese texts.
REST - Use cases for Annotation Management
Harvard:
Students and faculty can annotate. (Groups) Want to be able to group students further. Things might change between iterations. Image, but also text and video. Annotation with multimedia as well as text. HarvardX for the short term. Further out use for campus based courses too. Scholarly annotations not currently in scope. Tag based annotations, eg for assignments. Not necessarily enhancing the resources, geared towards learning instead.
Oxford:
Annotation of the content / manifest as part of Mellon project Longer term migration towards the standard for other annotations
NL Wales:
People who died in WW1 from Wales, project to transcribe the names. Need create, update (delete?) for the annotations. Could create the tool and release it for others to use.
Stanford:
Add annotations to existing manifests. Using LDP for the backend. Need to bring back annotations from 3rd party into repository. Crowd sourcing project where front end (Zooniverse) gets region of interest, and returns annotations.
Yale:
Access controlled scholarly research projects. Tagging. Different tools for create and update, eg create in mirador and update directly from blacklight.
Annotations not on IIIF resources – annotations on annotations. Faculty want to use in course situations, so iterations over years. Can the annotations be kept, and still be manageable?
Editors could publish annotations directly to the object, then crowd could suggest new ones, that get discussed and blessed.
Cornell:
Crowd sourced transcription.
e-codices:
Have an annotation tool, most of the annotations at the object level. Comments about manuscript, bibliography etc. Easy to add as the manifests are created on the fly. 3rd party site presenting content from e-codices, want to get the annotations back again.
Denmark:
Crowd sourcing annotations likely to be first use case to come up. Literary use case – make corrections in text of scanned book pages.
Europeana:
Projects working on annotations – annotation of images, maps. Portal will allow annotations from users. Kept at Europeana, but looking to feed back to the providers.
Norway:
Experiment with annotations related to geographical location. Annotations to correct OCR text – challenge for how to integrate corrections back into the ALTO Need to be able to filter annotations to not be overwhelmed Annotations seen as a good way to get user contributed data, rather than altering the manifests directly
BL:
Defer :)
Overall:
Desire to feed back annotations to the hosting repository, eg Yale makes annotation on BL content, would like to send that back to BL.
Scholars might work in private, then flip a switch to make them available. Might publish annotation list from Yale and provide the URI to NL Wales or whoever. BL agree – would like to know if someone annotated our content and link out to it.
Notification of the existence of an annotation list rather than creating new annotations abroad. Always some sort of workflow and curation – repos don’t typically want to reference individual annotations directly from anywhere.
Yale could put out a service where you came with your canvas ID you could find what was available. No guarantee that the annotations will be curated. How do you find blessed annotations?
e-codices, curation process is extremely important as well. Would like to bring anntotations to the back end and then accept or decline each. Search for everything on a canvas in a project/Layer.
Needs humans to do the curation. No annotation directly in Gallica due to this. Can annotate gallica resources in another site. Eg would be in trouble if the annotation content was illegal.
- In a tool, controlled environment, lists of annos are produced. Want to be able to dynamically pull them into the view.
- Publication process - we have good annotations, want to notify holder of the resource that the annotations are available.
Pub/Sub/Hub as as possible pattern. Discovery of annotation publishers to subscribe to via the hub.
Annotation practice is orthogonal to IIIF other than potentially hosting a hub. Need to be able to authenticate to annotation server.
Four IIIF concerns:
- building in notification to curate (eg a hub)
- providing a good experience in tools to render in a useful way
- AnnotationLists and in manifests as specific to IIIF
- Discovery of annotation services from a manifest
Defining functionality to be provided, rather than APIs at the moment. Discussion on iiif-discuss and fortnightly calls.
Showcase:
ACTION: Ruven, Bill, Rafael, Michael, Rashmi, Sean, Glen/Pridal, Gallica, Oxford to provide showcase item Future: Biblissima, Norway, Denmark, Poland
Tooling
Validators
- Arbitrary rotation – test size of returned image
- Check Encoded slash in the identifier?
- Check if everything that support is claimed actually works.
- Write a travis test recipe for how to use the validator.
SDK for the APIs
- Modular components.
Accessor methods for manifests, commonly needed bits. eg get a sequence: getSequence(?id) –> sequence
Something like:
manifest.getSequence(?id) --> sequence object // needs to deref external sequences
manifest.getCanvas(?id)
canvas.getAnnotations(?motivation, ?bodyType)
manifest.setPreferredLanguage(lang)
X.getMetadata(?language='') -- {"label" : ["value1", "value2"], "label2": ["value3"]}
X.listMetadata(?language='')
X.getLabel(?language='')
X.getDescription(?language='')
X.getAttribution(?language='')
util.isSafeHTML(value)
util.scrubHTML(value)
util.getSafeValue(value)
manifest.getTocStartRange()
manifest.getStartCanvas()
mutator methods: X.insert(Y) / push / pop / etc Could be used when references are resolved Do stuff with Ranges
Additional specific modules – do OSD based painting of canvas – do OpenLayers based painting of canvas – do …
Presentation Lite – getting started with minimal features Length of spec is intimidating. Tutorials for getting started. – non editor should do it Drew, Raphael :) Tutorial set of test images and metadata
Index of all the properties (alphabetical)
Links to validators, tutorials and fixtures should be more prominent.
Reference implementation of a client that handles all the fixture objects correctly Reference implementation to send your manifest URI to Button on validator to open in mirador (or other client) Start validator from info.json URI
Additional Notes from Thursday Editors meeting
Auth Principles
- MUST work for both Image and Presentation (and any future services)
- Identifiers for ‘degraded’ (i.e. different) resources (e.g. images) MUST be different
- To ensure caches aren’t invalidated
- To not break the interwebs
- E.g. links may fail but they should not be different for different users
- Authentication method is out of scope (as much as possible)
- E.g. OAuth, CAS, basic web auth
- Authorization roles/determination is out of scope
- E.g. no shared “student”
- How resources are degraded is out of scope, including description thereof
- E.g. Could be more compressed, could limit features, restrict qualities, watermark
- If you give access to info.json, you MUST give access to all the files it talks about
- The description of multiple authentication systems at once is out of scope
- Thus the info.json MUST have 0-1 services
- You must logout before getting prompted to authenticate again
- The service for authentication must provide the logout and somehow needs to clear it on the client if necessary
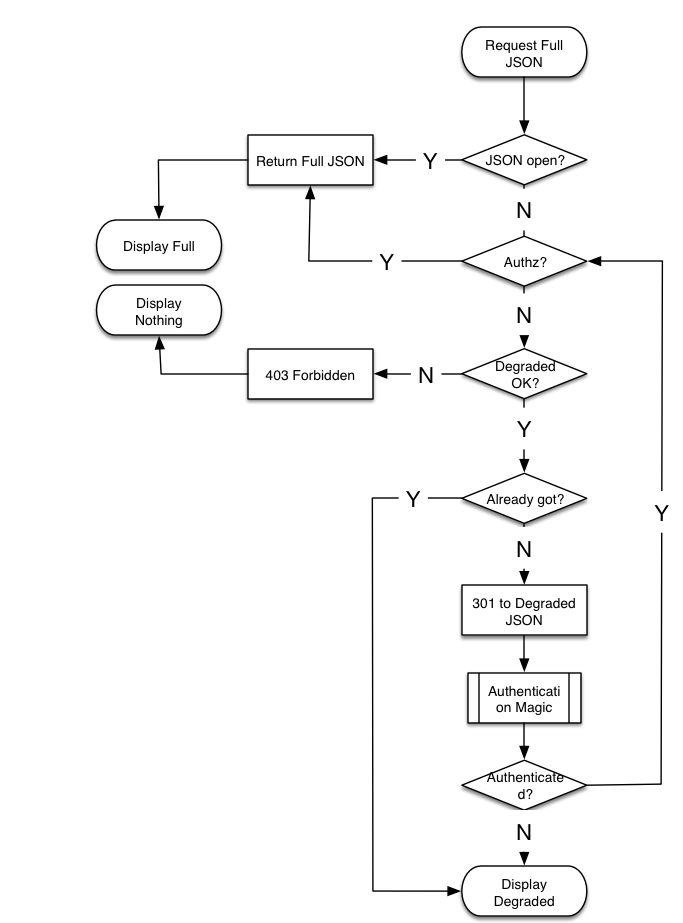 Workflow Strawman
Workflow Strawman
Notes to selves
- Don’t forget rights/attribution in info as well
- label to describe in human readable way the degradation
- make sure that multiple levels of degradation is possible
- E.g. thumbnail without any, max size within IP, sign in to get full version
- E.g. different methods of degradation for different roles
- No redirect loops :)
- Optional hint at manifest level that logins will be required, so please authenticate early and often
- Figure out CORS and cookies (Access-Control-Allow-Credentials), security implications
- Cookies are required as you don’t have access to request/response headers for image requests